Repo-Lookout: Sicherheitslücke beheben
Repo-Informationen öffentlich zugänglich
Eines schönen Tages bekam ich eine E-Mail von Repo Lookout. Darin stand, dass eines meiner Repositories für Zugriffe aus dem Internet freigegeben sei. Dies stelle ein potentielles Sicherheitsrisiko dar, da möglicherweise geheime Quelldateien, versteckte Funktionen oder sogar Passwörter enthalten sein könnten.
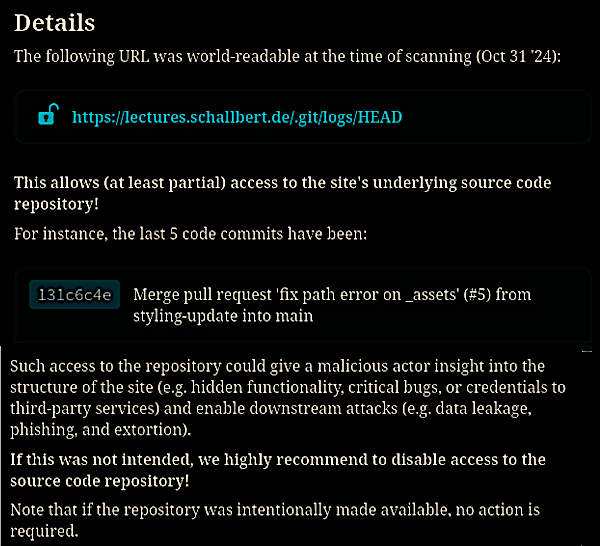
Zuerst hielt ich diese “Ihr-Repo-ist-nicht-sicher”-Warnung für einen Phishing-Versuch. Doch durch einfaches Eingeben der darin enthaltenen Links wurde klar, dass Repo Lookout Recht hatte und mein Lectures-Repo nicht nur wie von mir gewünscht öffentlich war, sondern dass auch die Metadaten zur Versionskontrolle offen auf dem Webserver lagen.
Ist das schlimm?
Normalerweise sollen innere Struktur und Konfiguration (Actions, Diskussionen, Wiki etc.) hinter einem Repository nicht öffentlich bleiben. Erst recht nicht, wenn das Repository als private angelegt ist. Doch auch bei öffentlichen Repos sollte niemand auf die Struktur dahinter zugreifen können.
Daher die Mission von Repo-Lookout:
“Find source code repositories that have been inadvertently exposed to the public and report them to the domain’s technical contact.” - Repo Lookout /about (Crissy Field GmbH)
In diesem Falle unkritisch, aber unerwartet und unschön.
Schadet mir nicht, weil mein Webserver die Dateien lediglich zum Abruf dort liegen hat und sie selbst bei Manipulation keine Rückwirkung auf mein Repository gehabt hätten. Außerdem hatte ich alle Secrets wie in diesem Artikel beschrieben in eigens angelegte Dateien ausgelagert, sodass sie nicht mehr in den Konfigurationsdateien auftauchen. Das Repository liegt zudem getrennt auf der Gitea-Server-Instanz. Dennoch sollte nur am Internet hängen, was ich bewusst freigeben möchte.
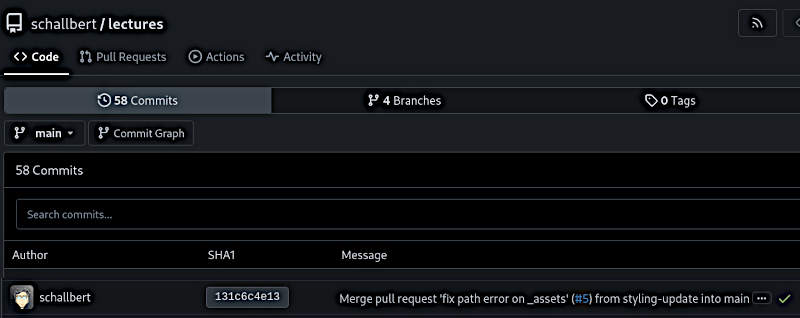
Der Bildausschnitt von Gitea zeigt denselben Commit wie die Warnung von Repo Lookout.
Wie es dazu kam
In der Deploy-Pipeline für meine Subdomain lectures.schallbert.de und Landing Page schallbert.de habe ich einen direkt-Checkout von der Gitea-Instanz zum Webserver Caddy. Dieser läuft automatisch an, sobald die main-Branches ein Update erhalten. Der Runner startet eine Checkout-Action, welche das Repository ins entsprechende Verzeichnis des Webservers kopiert.
Checkout-Action kopiert auch den .git-Ordner
Dabei wird der .git-Ordner einfach mit aufgesetzt. Dort drin liegen alle von der Versionskontrollsoftware benötigten Daten zur Zustandsverwaltung des Repos. Den Kopiervorgang selbst kann ich auf Gitea nicht sehen, denn dort taucht der versteckte .git-Ordner gar nicht erst im Verzeichnis auf. Verständlich, denn auf Basis dieses Ordners findet die gesamte Darstellung auf Gitea statt.
So blieb das unerwünschte Verhalten unter meinem Radar - und laut Repo Lookout bin ich bei Weitem nicht der Einzige, dem es so geht.
Option 1: Fix auf dem Webserver
Die naheliegendste Lösung ist, den Zugriff auf die Datei serverseitig zu blockieren. Dies kostet nur wenige Ressourcen und ist leicht einzurichten.
Dieser Foreneintrag zeigt, wie das geht: hide-entire-folder-caddyfile. Für meine zu schützenden Dateien füge ich also folgende Einträge der Caddyfile hinzu:
# /caddy2/Caddyfile
# [...]
respond /.git/* "Access denied" 403
respond /.gitea/* "Access denied" 403
Damit sage ich Caddy, dass es bei Aufruf einer beliebigen Datei /* im Ordner /.git mit dem Fehlercode 403 “Forbidden” antworten soll. Dabei ist die Wildcard (*) unbedingt erforderlich, denn sonst wird lediglich der Ordner selbst und nicht die enthaltenen Dateien gesperrt.
Zur Kontrolle prüfe ich was passiert, wenn ich die Git Logs anfrage:
# Terminal
curl <lectures.schallbert.de>/.git/logs/HEAD
Access denied
Funktioniert prima!
Option 2: Fix in der Checkout-Action
Es gibt allerdings eine noch viel elegantere Lösung: bereits vorher in der Pipeline dafür sorgen, dass der Ordner gar nicht erst auf dem Server auftaucht.
Variante 1: Mit Hilfe von sparse-checkout
sparse-checkout ermöglicht die Auswahl von Ordnern und Dateien, die zum Checkout gehören sollen. Alle anderen Dateien im Repository bleiben unberührt und tauchen im Branch nicht auf. Dies spart vor allem bei großen Repositories Zeit und Speicherplatz. Macht aber natürlich nur Sinn wenn bereits vorher bekannt ist, dass nicht alle Dateien angefasst werden müssen.
Negativliste für sparse-checkout
In meinem Falle will ich die oben erwähnten Ordner gerade nicht per Checkout auf den Server kopieren, den ganzen Rest aber schon. Wie ich das hinbekomme? Mit Hilfe der Negation im no-cone mode.
“The user has explicitly said ‘I want these directories and not those directories.’” - Derrick Stolee, Microsoft, auf Github
In der Anleitung zu Checkout-Action steht, dass sparse-checkout auch für die vom Runner automatisierte Aktion unterstützt wird.
Nun programmiere ich mit Hilfe des Github Actions Cheet Sheet:
# /.gitea/workflows/deploy-lectures.yml
# [...]
steps:
- name: --- CHECKOUT ---
uses: actions/checkout@v4
with:
path: ./tmp
sparse-checkout: |
/*
!.git
!.gitea
sparse-checkout-cone-mode: false
# [...]
Zur Erläuterung: Das Skript zum Veröffentlichen auf meinem Webserver verwendet die Aktion checkout, Unterfunktion sparse-checkout und bezieht sämtliche Dateien im Ordner im Stammverzeichnis tmp und darunter ein bis auf .git und .gitea.
Was ist der No-Cone Mode?
Standardmäßig erwartet sparse-checkout eine Liste von Ordnern, die für den Checkout erfasst werden sollen. Im no-cone Modus wird stattdessen eine Liste von Patterns erwartet. Hier sind sämtliche Operatoren möglich, die auch in der .gitignore zum Spezifizieren von Dateien, Ordnern, Auslassungen etc. verwendet werden können. Dies ermöglicht mir den Ausschluss bestimmter Ordner, hat aber einige gewichige Nachteile. Durch viel höhere Komplexität der Pattern-Befehle, die damit einhergehende Fehleranfälligkeit sowie die deutlich rechenintensivere Auswertung bei größeren Repositories wird die Verwendung des no-cone Mode nicht empfohlen und ist in der Dokumentation als “deprecated” (überholt) angegeben. Dennoch, probieren geht über Studieren!
Test mit sparse-checkout
Nun lade ich die Action auf meine Gitea-Instanz hoch und lass meinen runner einmal drüber laufen. Anschließend logge ich mich auf dem Webserver ein und schaue, ob der .git-Ordner erstellt wurde oder nicht:
lectures# ls -la
[...]
drwxr-xr-x 8 root root 4096 Dec 20 10:41 .git
[...]
Mist, der Ordner ist ja immer noch da. Ich schaue in den Logs der Action auf meiner Gitea-Instanz nach:
[...]
hint: git branch -m <name>
Initialized empty Git repository in /workspace/schallbert/lectures/tmp/.git/
[...]
::group::Setting up sparse checkout
[command]/usr/bin/git config core.sparseCheckout true
An sparse-checkout liegt es also nicht. Dafür aber an der Art und Weise, wie checkout funktioniert: Offensichtlich wird für ein ordentliches Aufsetzen des Repository auf meinem Webserver der .git-Ordner zwingend benötigt. Also bleibt mir nur übrig, ihn nach dem Auschecken automatisch zu löschen.
Variante 2: rm -rf
Und so probiere ich es mit Gewalt:
# /.gitea/workflows/deploy-lectures.yml
# [...]
steps:
- name: --- CHECKOUT ---
uses: actions/checkout@v4
with:
path: ./tmp
- name: --- REMOVE TEMPORARY FILES ---
run: |
rm -rfv ./tmp/.git ./tmp/.gitea
# [...]
Nun endlich taucht der .git-Ordner auf meinem Webserver nicht mehr auf und mein “Repo-Leak” ist geflickt. Nochmal danke an Repo Lookout!
Fazit
Ich hatte hier das Problem, dass der versteckte .git-Ordner, wo Konfiguration und Struktur von Repositories gespeichert werden, unbeabsichtigt und ohne mein Wissen auf meinem Webserver veröffentlicht waren.
Ich habe hier zwei funktionierende Optionen zur Lösung des Problems vorgestellt:
- Ein Zugriffsverbot auf dem Webserver einrichten
- Die Pipeline so umbauen, dass sie den
.git-Ordner nach erfolgtem Ausrollen selbstständig löscht.
Die zweite Option ist zwar etwas aufwendiger einzubauen, doch packt sie das Problem bei der Wurzel, anstatt lediglich die Symptome zu beheben. Außerdem entspricht sie dem ersten Grundsatz aus dem Datenschutz: Datenminimierung geht vor Schutzmaßnahmen.
“Was nicht existiert, kann nicht verloren gehen” - Schallbert