Fehler-Logdateien versenden
In diesem Artikel schaue ich mir an, wie ich “Monitoring” für meinen Server einrichte. Anwendungen und Dienste sollen mir im Fehlerfalle Benachrichtigungen senden können.
Worum geht es hier?
- Sendemechaniken kennenlernen und auswählen
- Testnachrichten verfassen und die Automation verifizieren
- Fehlerbericht von Borgmatic automatisch senden
- Senden von Runner-logs durch Gitea
- Benachrichtigung bei Login auf meinem Server per ssh
- Erstellen und Senden eigener Logs zu Server-Update / Server-Fehlern
Verifikation und Überwachung
Ich möchte nach dem Ausführen einer Automation wissen, ob sie erfolgreich durchgeführt wurde und alle Programme und Dienste ihre Arbeit erwartungsgemäß aufgenommen haben. Dies soll für jegliche Automation gelten - ob es sich konkret um das Senden eines Updates, die Anfertigung automatischer Backups oder eine Action von Gitea handelt, muss egal sein.
Normalerweise würde ich für so etwas Berichtsmechanismen von act_runner verwenden. Im Falle eines Server-Updates steht der Runner durch den bereits im Artikel Serverkonfiguration ausrollen erwähnten Zirkelbezug nicht zur Verfügung, da zeitweise alle Anwendungen heruntergefahren werden müssen.
Zudem kann es sein, dass Anwendungen eigene Vorgehensweisen haben, Monitoring zu betreiben. Also muss ich mir Mechanismen anschauen, mit denen ich leicht an die Informationen herankomme.
Was zeichnet ein gutes Monitoring für mich aus?
- Es ist unaufdringlich, meldet sich also nur im Fehlerfall oder bei ungewöhnlichen Vorgängen.
- Es liefert spezifische Informationen und gut zu verstehende Fehlermeldungen.
- Es nutzt einen Nachrichtenkanal, der auch bei Absturz des zu überwachenden Systems funktioniert.
- Es stellt Berichte und Fehlermeldungen isoliert von anderen Themen dar und vermischt nichts.
- Es fasst sich kurz.
Methoden automatischer Berichterstattung
Diesen Abschnitt gliedere ich ich auf. Im Allgemeinen Teil gehe ich auf das mir auf dem Ubuntu-Server zur Verfügung stehende Bordwerkzeug zum asynchronen Monitoring ein. Danach schaue ich mir die bei meinen Diensten teils eingebauten Lösungen bzw. mit ihnen kompatible Anwendungen an. Dabei möchte ich mich nicht auf das klassische Instrument der E-Mail beschränken, sondern auch kurz “modernere” Kommunikationskanäle wie Messengerprogramme oder RSS-Feed beleuchten.
Mail per Konsole - curl
Versand von Mails als Benachrichtigungen sind in vielen Firmen üblich. Dies geht mit Linux meist sogar ganz ohne zusätzliche Programme: Das standardmäßig vorhandene curl kann hier bereits weiterhelfen. curl it ein Programm zum Datentransfer von oder zu einem Server. Gebe ich meinen Blog als Ziel ein, bekomme ich die HTML-Seite als Textdatei auf die Konsole ausgegeben:
curl https://blog.schallbert.de
Bei der Gelegenheit fällt mir auf, wie viel unnötige Daten meine Blogsoftware erzeugt. Da werde ich später mal aufräumen müssen. Zurück zum Thema: Man kann curl allerdings auch nutzen, um ein beliebiges Webbackend anzusprechen - Zum Beispiel einen Mailserver:
# copied from https://stackoverflow.com/questions/8260858/how-to-send-email-from-terminal
curl --url 'smtps://smtp.gmail.com:465' --ssl-reqd \
--mail-from 'from-email@gmail.com' \
--mail-rcpt 'to-email@gmail.com' \
--user 'from-email@gmail.com:YourPassword' \
-T <(echo -e 'From: from-email@gmail.com\nTo: to-email@gmail.com\nSubject: Curl Test\n\nHello')
Dies funktioniert nur dann auch für meinen Mail-Provider, wenn ich Logins durch externe Clients zulasse. Google nennt diese z.B. “weniger sichere Apps”. Ich bin wie in meinem Beitrag Server-Konfiguration mit Git beschrieben kein Fan davon, Secrets irgendwo hart hineinzuschreiben - daher würde ich den direkten Weg über curl eher nicht nutzen.
Mail per Konsole - mail, mailx, mailutils, swaks
Wer all die Konfigurationsinformationen für den Server und Secrets nicht immer mitgeben möchte, dem stehen diverse handliche Werkzeuge für die Konsole wie mailutils oder swaks zur Verfügung. Hier wird die Verbindung zum Mailserver über das Werkzeug einmalig konfiguriert und kann in z.B. in Umgebungsvariablen abgelegt werden. Die Syntax variiert von Programm zu Programm, hinten kommt aber stets eine Mail heraus.
An sich eine simple Lösung. Der einzige große Nachteil dabei für mich ist, dass sich hier Informationsdomänen vermischen. Ich hätte nur ungern noch einen “Berichtsthread” in meinen Mails, nach dem ich im Wust der Nachrichten irgendwann würde suchen müssen. Bei Benachrichtigungen auf anderen Kanälen kann ich zudem ein automatisches Verfallsdatum einstellen, sodass sie nach eingestellter Zeit aus meiner Liste verschwinden.
RSS Feed erzeugen
Ungewöhnlich aber möglich: Ich könnte das Monitoring als RSS-Feed wie meinen Blog auch (schallberts-blog-feed) z.B. per Jekyll-Instanz erzeugen und als Website online stellen. Dieser wäre leicht zu abonnieren, mit praktisch jedem Reader zu lesen und ich könnte ihn sogar für jede Applikation ganz einfach getrennt vorsehen. Doch es gibt offensichtliche Nachteile:
- Hoher Aufwand: Gitea runner mit Jekyll-Instanz, Webserver und Subdomain erforderlich.
- Öffentlich verfügbar: Plötzlich werden Bauvorgänge, Updates, Upgrades und Fehlermeldungen für jedermann zugänglich.
- Fehleranfällig: Schmiert Gitea, der Runner, mein Proxy oder der Webserver ab, bekomme ich keine Berichte.
Spätestens mit dem letzten Punkt ist diese Option für mich raus. Ich möchte ja gerade dann einen Bericht bekommen, wenn meine Applikationen nicht das tun, was sie sollen.
Werfen wir nun mal einen Blick auf die von mir bereits betriebenen Anwendungen und schauen, wie sie dieses Problem angehen.
borgmatic
Borgmatic bringt von Haus aus Kompabitilität zu einer Menge Monitoring-Optionen mit. Darunter befinden sich apprise, ntfy, healthchecks, cronitor, pagerduty, cronhub und grafana.
- Apprise ist eine Bibliothek. Sie ist quelloffen und kann von einer bestehenden Anwendung als Abhängigkeit eingebunden werden. Wie ein Adapter ermöglicht sie die asynchrone Kommunikation der Anwendung mit diversen verschiedenen Kommunikationsdiensten wie SMS, Mail, Messenger (z.B. Signal), diverse Heimautomation oder den Benachrichtigungssystemen diverser Betriebssysteme. Letzteres funktioniert allerdings nur auf der lokalen Maschine. Der Trigger für die Kommunikation muss dabei stets von der Anwendung ausgehen.
- ntfy ist ein Push-Benachrichtigungsdienst. Er ist quelloffen und kann sowohl selbst gehostet als auch über eine Webanwendung als Dienstleistung in Anspruch genommen werden. Apprise z.B. unterstützt ntfy als Kommunikationsdienst. Der Aufbau ist recht einfach und funktioniert wie bei MQTT auch über einen Publication-Subscription bzw. Broker-Client Mechanismus, allerdings HTTP-basiert.
- Healthchecks ist ein Dienst. Er ist quelloffen und kann selbst gehostet werden. Der Dienst ist dazu da, regelmäßige Aktivitäten zu überwachen und kann als Totmannschalter fungieren: Erfolgt anders als erwartet keine Rückmeldung vom überwachten Programm, so kann er selbst eine Fehlermeldung absetzen. Diese kann wiederum an diverse Kommunikationsdienste gesendet werden.
- Cronitor ist eine Monitoringlösung und Webanwendung, die neben den von mir benötigten Benachrichtigungen eine Menge Analysetools, Leistungsmessungen und Metriken - zumeist gegen Geld - bereitstellt. Es gibt zwar einen kostenfreien “Hacker”-Account mit begrenztem Funktionsumfang, jedoch ist auch dieses Werkzeug mir entschieden zu groß und zu komplex.
- PagerDuty sieht sich als kommerzielle “Operations” Plattform, die sowohl “Incident Management”, Automation, “Business Operations”, “AIOps” etc. bereitstellt. Ist für mich direkt raus. Spätestens beim Wort “AIOps” 😅
- cronhub sieht mir wie eine kommerzielle Webanwendung aus, die ähnlich wie Healthchecks Cron-Jobs erstellen, überwachen und bei Fehlern melden kann. Sie ist für mich uninteressant, denn sie scheint weder open source zu sein noch könnte ich sie selbst hosten.
- Grafana ist eine Open-Source-Webanwendung, die entweder selbst gehostet oder als Cloud-Dienst verwendet werden kann. Obwohl viele größere Unternehmen und Projekte die Anwendung nutzen, ist sie für meine Zwecke um Größenordnungen zu umfang- und funktionsreich.
fail2ban
Fail2ban hat keine Automationslösung wie borgmatic. Es erzeugt schlicht Logdateien die ausgewertet werden müssten, um Inhalte für Benachrichtigungen zu gewinnen. Mir fällt im Moment nichts ein, was ich unbedingt von Fail2ban wissen müsste. Daher erstelle ich mir hierfür erst einmal keine Berichte.
Gitea
Bei Gitea lassen sich die Logdateien sehr feingliedrig konfigurieren. So können Access Logs getrennt von Service Logs, Repository Logs oder Action Logs herausgeschrieben und dann weiterverarbeitet werden. Als Benachrichtigungssystem bietet Gitea nach meiner Recherche ausschließlich einen mailer an. Dieser ist meiner Ansicht nach vor Allem für Repository- und Action Logs gedacht.
Auch hier würde es mir am meisten bringen, die Logs zu analysieren und bei Bedarf einen Bericht selbst zu erstellen.
Server
Das Ausrollen meiner Server-Konfigurationsdateien übernehme ich per Skript ja sowieso schon selber. Also könnte ich auch hier im Fehlerfalle die Logs in eine Datei umleiten und sie dann einem Bericht in einen beliebigen Kanal anhängen.
Außerdem wären erfolgreiche Logins auf dem Server selbst eine Nachricht an mich wert. Dann kann ich sofort feststellen, ob ich das selbst war oder nicht.
Die Auswahl des Berichtsprogramms
Ich muss nicht nur ein Monitoring-Programm heraussuchen, sondern auch einen Kommunikationsdienst wählen über den die Berichte versendet werden.
Berichtsprogramm
| Programm | Vorteil | Nachteil |
|---|---|---|
| curl | simpel | Konfiguration muss mitgegeben werden |
| funktioniert super einfach mit ntfy1 | Keine Überwachung bei Absturz des Servers | |
| Bordwerkzeug | ||
| kein Service erforderlich | ||
| Apprise | ermöglicht Einbindung der Signal-Api2 | Komplex im Zusammenspiel mit externen Diensten3 |
| kein Service erforderlich | ||
| Healthchecks | Kann als Watchdog/Totmannschalter agieren | Registrierung erforderlich |
| Kann lokal gehostet4 werden | Lokales Hosting widerspricht Watchdog-Konzept |
Ich habe ja nur einen kleinen Server mit ein paar wenigen Anwendungen. Daher halte ich es hier so einfach wie möglich und wähle Apprise für Dienste wie borgmatic, die diese Bibliothek sowieso mitbringen und curl für jene, deren Berichtsmechanik ich selbst programmieren muss.
Kommunikationsweg
| Programm | Vorteil | Nachteil |
|---|---|---|
| SMS | Hohe Zuverlässigkeit | Registrierung erforderlich |
| Beschränkung auf wenige Zeichen | ||
| Keine Anhänge möglich | ||
| Keine Topics, Domänenvermischung | ||
| einfach einzurichten | Schlechte Durchsuchbarkeit | |
| RSS-Feed | Gute Sortierbarkeit | Kompliziert einzurichten, fehleranfällig |
| Client sehr leichtgewichtig | Lokales Hosting widerspricht Watchdog-Konzept | |
| Inhalte öffentlich verfügbar | ||
| ntfy | Simpel und leichtgewichtig | Registrierung optional bei Web-Nutzung |
| Client zweckorientiert | Unsicher: Keine Verschlüsselung ohne Registrierung | |
| Kostenlos für Kleinanwender | ||
| Unabhängig von der eigenen Maschine | ||
| Signal | “Note to self” einfach einzurichten | Einrichtung und Konfiguration der Signal-API komplex |
| Unabhängig von der eigenen Maschine | Topics etwas schwierig umzusetzen | |
| Nutzlos bei Absturz des Servers |
SMS, Mail und RSS-Feed sind durch teils oben bereits erläuterte Nachteile für mich bereits raus. Bleiben also ntfy und Signal. ntfy besticht durch seine Einfachheit: HTTP PUSH-request auf ein selbst definiertes “Topic” senden und selbiges auf dem Handy abonnieren - fertig. Es ist auch gut erweiterbar, denn durch self-hosting kann ich später bei Bedarf die Sicherheit erhöhen (Verschlüsselung) und das Sendeverhalten steuern. Signal hingegen macht einen eigenen Client mit verhältnismäßig aufwändiger Konfiguration erforderlich. Außerdem müssten die Geräte Server-Handy verbunden werden, sodass nicht einfach neue Abonnenten hinzuzufügen sind. Dafür ist die Übertragung bestens Ende-zu-Ende gesichert, ich muss mich nicht registrieren und kostenlos ist es auch noch.
Vorerst entscheide ich mich auch hier für die weniger komplexe Lösung mit ntfy.
Logging
Gut. Nun ist geklärt, dass ich per curl und apprise über den ntfy-Dienst nach Hause telefoniere. Nun schaue ich mal, welcher Inhalt zu übermitteln ist und wie ich möglichst unaufdringlich, dabei aber kurz und prägnant bleibe.
Wann sollen Logs gesendet werden?
- borgmatic: Wenn ein Backup fehlschlägt
- Bei erfolgreichem Login auf meinen Server oder Gitea
- Nach Ausrollen eines Updates der Server-Konfiguration
- docker: Falls eine Applikation ausfällt oder nicht hochfährt
- gitea: Fehlgeschlagener Durchlauf von act_runner
Was gehört für mich in einen Bericht?
Ich möchte die klassischen “W-Fragen” beantwortet bekommen.
- Wann ist es passiert (Zeitstempel)?
- Welche Anwendung berichtet?
- Was ist passiert?
- Wo (Modul, Codezeile) etc. ist das passiert?
- Wie viele Verletzte (Schweregrad, Recovery)?
Eine Benachrichtigung sieht dann etwa so aus:
TIMESTAMP APPLICATION PRIORITY MESSAGE EFFECT DETAIL
Rohfassung eines Berichts
Eine ntfy-Nachricht könnte ungefähr so aussehen:
curl \
-H "Title: Fehler Borgmatic" \
-H "Priority: urgent" \
-H "Tags: warning" \
-d "YYYY-MM-DD HH:MM:SS Backup-Erstellung abgebrochen. Zugriff auf Repository blockiert" \
ntfy.sh/schallberts-topic
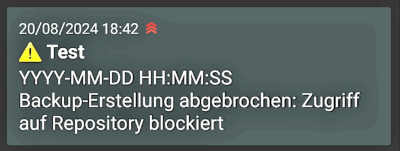 Ich installiere die entsprechende App auf meinem Handy, registriere mich auf das “Topic” und sende die Nachricht ab. Es ist schön, wenn Dinge einfach funktionieren!
Aha, die App zeigt den Zeitpunkt des Einganges an. Das ist mir genau genug.
Ich installiere die entsprechende App auf meinem Handy, registriere mich auf das “Topic” und sende die Nachricht ab. Es ist schön, wenn Dinge einfach funktionieren!
Aha, die App zeigt den Zeitpunkt des Einganges an. Das ist mir genau genug.
Durchführung
Ich nehme mir hier nacheinander alle Dienste vor, für die ich gern Benachrichtigungen einrichten möchte.
borgmatic
Starten wir mit einem Pilotversuch wieder in kleinen Schritten. Als Erstes konfiguriere ich Borgmatic zum Senden einer Nachricht über Apprise an ntfy bei Fehlschlag der Backup-Erstellung:
# /borgmatic.d/config.yml
on_error:
- echo "Error while creating a backup."
- apprise -vv --title "Borgmatic Error"
--body "Could not run {output}. Aborted {error}."
ntfy://schallberts-topic
Dann teste ich das Kommando, indem ich innerhalb des Borgmatic-Containers apprise anspreche. Und tatsächlich, es funktioniert. Aber der Weg hierhin hat mich locker eine Stunde gekostet, da die yml mit ihren Syntaxregeln sogar innerhalb von Strings interpretiert und borgmatic aufgrund von : sowie - Zeichen ständig die Konfigurationsdatei nicht lesen wollte. Wenn ihr einen Fehler sieht ähnlich diesem hier:
At 'on_error[1]': {'apprise -vv --title "Borgmatic Error" --body "Could not run {output}': 'Aborted {error}." ntfy://schallberts-topic'} is not of type 'string'
Daran ist zu erkennen, dass die Interpretation von Zeichen oder Einrückungen schiefgelaufen ist und die Zeichensetzung zu prüfen ist. Alternativ kann auch der Pipe-Operator | verwendet werden, um ein Kommando zu kombinieren. Referenz: yml-Spezifikation
Server
Eine Anwendung von ntfy zur Überwachung von Logins auf einem Server findet sich bereits in der Dokumentation von ntfy selbst. Die Beschreibung zeigt, dass so etwas leicht selbst umzusetzen ist und gibt unter Verwendung von Pluggable Authentication Modules (PAM-Bibliothek) ein tolles Beispiel.
Am Ende der Datei sshd im Verzeichnis etc/pam.d folgenden Code einfügen:
session optional pam_exec.so /usr/bin/ntfy-ssh-login.sh
Diese Zeile sagt PAM, dass sie bei Öffnen einer session per ssh das ausführende Modul pam_exec aufrufen soll, welches dann das hernach angegebene Skript abspult. Der Wert optional bedeutet, dass die Konfigurationsdatei auch bei Fehlschlag der Aktion weiter durchlaufen werden soll. Mehr Details zum Umgang mit PAM gibt es z.B. auf Baeldung.
Anschließend ist im Skript ntfy-ssh-login.sh schlicht der ntfy-Aufruf zu hinterlegen, wenn das Skript feststellt, dass PAM ein open_session Event festgestellt hat.
Genau so habe ich es bei mir umgesetzt und es funktioniert auf Anhieb. Klasse! Der einzige Nachteil: Diese Modifikation habe ich direkt auf dem Server gemacht. Ohne Container und außerhalb meiner Konfigurations-Sicherung. Wenn ich den Server jetzt aus irgendeinem Grund neu aufsetzen muss, ist die Änderung im PAM futsch und ich bekomme keine Benachrichtigungen mehr, bis ich die Änderung manuell erneut einpflege.
Server-Konfiguration
Für das Senden eines Berichts nach Ausführen der Konfigurationsautomation muss ich eigentlich nur das im Rahmen des letzten Artikel verfasste server-config-action Skript anpassen.
Zunächst möchte ich informiert werden, wenn das Skript fehlerfrei durchlief. Dafür füge ich am Ende der Datei einen curl-Befehl ein.
# server-config-action.sh
# action commands...
# [...]
# send success notification
curl \
-H "Title: server-config-action" \
-H "Priority: low" \
-H "Tags: white_check_mark" \
-d "Rollout successful" \
ntfy.sh/schallbert-server-config-push-topic
Sollte das Skript allerdings nicht fehlerfrei durchlaufen, so möchte ich folgendes tun:
- Aktionen nach Auftreten des Fehlers abbrechen
- Ein Fehler-Log erstellen
- Dieses Log versenden
Den ersten Punkt kann ich durch Hinzufügen einer Falle (Englisch “Trap”) für Fehler erreichen:
# server-config-action.sh
trap 'handle_error $LINENO' ERR
# action commands...
Hiermit wird die Funktion handle_error aufgerufen. Ihr wird die Zeilennummer mitgegeben, an der der Fehler ERR auftrat. Damit decke ich auch Fehler ab, die beim Neustart der Container entstehen können. Das Fehler-Log erstelle ich mir durch Wegschreiben der Ausgabe der einzelnen Skriptbefehle. Dies erreiche ich mit der folgenden Zeile:
# server-config-action.sh
exec 3>&1 1>server-config-action.log 2>&1
# action commands ...
Jeglicher Standard-Output stdout soll mit diesem Befehl an den Dateideskriptor 3, hier angegeben mit der Logdatai server-config-action-log, überschreibend weitergereicht werden. Für “Anhängen” müssten es zwei Umleitungsoperatoren >>5 sein. Somit ersetzt die Logdatei die Konsolenausgabe, welche ich im vorigen Artikel noch an dieser Stelle hatte.
Um das Log zugesandt zu bekommen, definiere ich nun folgende Funktion am Anfang des Bash-Skripts:
# server-config-action.sh
# on error, send a notification
handle_error() {
# stop redirecting to file
exec 1>&3 1>&2
curl \
-H "Title: server-config-action FAILED" \
-H "Priority: high" \
-H "Tags: x" \
-T server-config-action.log \
-H "Filename: server-config-action.log" \
ntfy.sh/schallbert-server-config-push-topic
exit 1
}
# set error trap
# redirect stdout and stderr to file
# action commands...
Gitea
Für Berichte von Github Actions gibt es bereits ein existierendes Beispiel auf ntfy_examples/#github-actions. Und das Beste: Da der act_runner von Gitea an den wesentlichen Stellen in den Umgebungsparametern kompatibel ist, funktioniert das Senden an ntfy bei mir auf Anhieb. In der Workflow-Datei des runners muss nur der auf der Website angegebene curl-Befehl angegeben werden und fertig.
Ergebnis
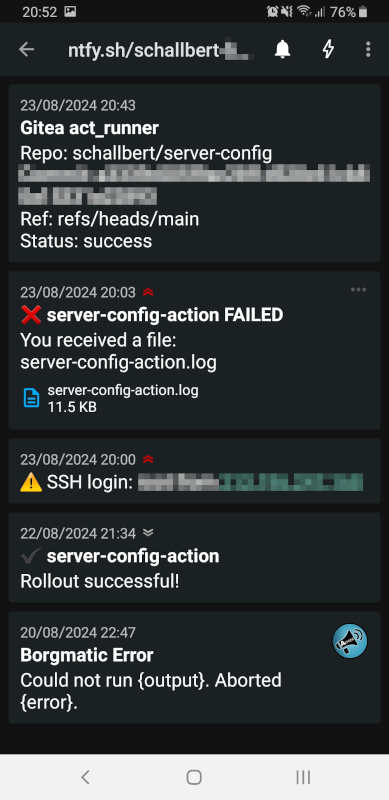
Hiermit sind jetzt fünf Benachrichtigungen über die wichtigsten Vorgänge auf meinem Server eingerichtet. Ich habe die zugrundeliegenden Mechaniken verstanden und kann jederzeit weitere Benachrichtigungen erstellen, wenn ich sie benötige. Löse ich alle Benachrichtigungen testweise aus, zeigt mein Handy das dargestellte Bild.
Eine Unabhängigkeit vom zu überwachenden System habe ich noch nicht erreicht. Die Benachrichtigungen gehen sämtlich von der betroffenen Maschine aus und es bestehen zum Teil sogar Abhängigkeiten zwischen Docker-Containern. Der act_runner muss sich zum Beispiel über Websockets mit Gitea verbinden. Und das funktioniert nur, wenn Caddy den Reverse Proxy bereitstellt.
Stelle ich in den nächsten Monaten fest, dass ein Dienst “unter meinem Radar” nicht mehr arbeitsfähig ist, werde ich diese Unabhängigkeit herstellen müssen und entsprechend darüber berichten.
-
Kontext zur Signal-API ↩
-
Bericht von
asad-awadiazur Einrichtung der Signal-API ↩ -
Healthchecks ist direkt verfügbar als Docker-Image. ↩
-
Übrigens sind die Operatoren
<<und>>für mich nicht schwer zu merken, denn früher habe ich viel mit der ProgrammierspracheCzu tun gehabt. Dort - und in vielen anderen Programmiersprachen auch - sind dies Shift-Operatoren, die einen Wert bitweise “verschieben” bzw. ein Feld auf ein anderes schieben können. Bei den RISC Architekturen, die ich damals verwendet habe, war die Schiebe-Operation “billig”, also sehr schnell und speicherplatzschonend umgesetzt. ↩